
五倍吞吐量,性能全面包围Transformer:新架构Mamba引爆AI圈
在别的领域,如果你想形容一个东西非常重要,你可能将其形容为「撑起了某领域的半壁江山」。但在 AI 大模型领域,Transformer 架构不能这么形容,因为它几乎撑起了「整个江山」。
自2017年被提出以来,Transformer 已经成为 AI 大模型的主流架构,但随着模型规模的扩展和需要处理的序列不断变长,Transformer 的局限性也逐渐凸显。一个很明显的缺陷是:Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加32倍时,计算量可能会增长1000倍,计算效率非常低。
为了克服这些缺陷,研究者们开发出了很多注意力机制的高效变体,但这往往以牺牲其有效性特为代价。到目前为止,这些变体都还没有被证明能在不同领域发挥有效作用。
最近,一项名为「Mamba」的研究似乎打破了这一局面。

在这篇论文中,研究者提出了一种新的架构 ——「选择性状态空间模型( selective state space model)」。它在多个方面改进了先前的工作。
作者表示,「Mamba」在语言建模方面可以媲美甚至击败 Transformer。而且,它可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现5倍的推理吞吐量提升。
消息一出,人们纷纷点赞,有人表示已经迫不及待想要把它用在大模型上了。
作为通用序列模型的骨干,Mamba 在语言、音频和基因组学等多种模态中都达到了 SOTA 性能。在语言建模方面,无论是预训练还是下游评估,他们的 Mamba-3B 模型都优于同等规模的 Transformer 模型,并能与两倍于其规模的 Transformer 模型相媲美。

这篇论文的作者只有两位,一位是卡内基梅隆大学机器学习系助理教授 Albert Gu,另一位是 Together.AI 首席科学家、普林斯顿大学计算机科学助理教授(即将上任)Tri Dao。
Albert Gu 表示,这项研究的一个重要创新是引入了一个名为「选择性 SSM」的架构,该架构是 Albert Gu 此前主导研发的 S4架构(Structured State Spaces for Sequence Modeling ,用于序列建模的结构化状态空间)的一个简单泛化,可以有选择地决定关注还是忽略传入的输入。一个「小小的改变」—— 让某些参数成为输入的函数,结果却非常有效。

值得一提的是,S4是一个非常成功的架构。此前,它成功地对 Long Range Arena (LRA) 中的长程依赖进行了建模,并成为首个在 Path-X 上获得高于平均性能的模型。更具体地说,S4是一类用于深度学习的序列模型,与 RNN、CNN 和经典的状态空间模型(State Space Model,SSM)广泛相关。SSM 是独立的序列转换,可被整合到端到端神经网络架构中( SSM 架构有时也称 SSNN,它与 SSM 层的关系就像 CNN 与线性卷积层的关系一样)。Mamba 论文也讨论了一些著名的 SSM 架构,比如 Linear attention、H3、Hyena、RetNet、RWKV,其中许多也将作为论文研究的基线。Mamba 的成功让 Albert Gu 对 SSM 的未来充满了信心。
Tri Dao 则是FlashAttention、Flash Attention v2、Flash-Decoding的作者。FlashAttention 是一种对注意力计算进行重新排序并利用经典技术(平铺、重新计算)加快速度并将内存使用从序列长度的二次减少到线性的算法。Flash Attention v2、Flash-Decoding 都是建立在 Flash Attention 基础上的后续工作,把大模型的长文本推理效率不断推向极限。在 Mamba 之前,Tri Dao 和 Albert Gu 也有过合作。

另外,这项研究的模型代码和预训练的检查点是开源的,参见以下链接:https://github.com/state-spaces/mamba.

论文链接:https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf
方法创新
论文第3.1节介绍了如何利用合成任务的直觉来启发选择机制,第3.2节解释了如何将这一机制纳入状态空间模型。由此产生的时变 SSM 不能使用卷积,导致了高效计算的技术难题。研究者采用了一种硬件感知算法,利用当前硬件的内存层次结构来克服这一难题(第3.3节)。第3.4节描述了一个简单的 SSM 架构,不需要注意力,甚至不需要 MLP 块。第3.5节讨论了选择机制的一些其他特性。
选择机制
研究者发现了此前模型的一个关键局限:以依赖输入的方式高效选择数据的能力(即关注或忽略特定输入)。
序列建模的一个基本方法是将上下文压缩到更小的状态,我们可以从这个角度来看待当下流行的序列模型。例如,注意力既高效又低效,因为它根本没有明确压缩上下文。这一点可以从自回归推理需要明确存储整个上下文(即 KV 缓存)这一事实中看出,这直接导致了 Transformer 缓慢的线性时间推理和二次时间训练。
递归模型的效率很高,因为它们的状态是有限的,这意味着恒定时间推理和线性时间训练。然而,它们的高效性受限于这种状态对上下文的压缩程度。
为了理解这一原理,下图展示了两个合成任务的运行示例:
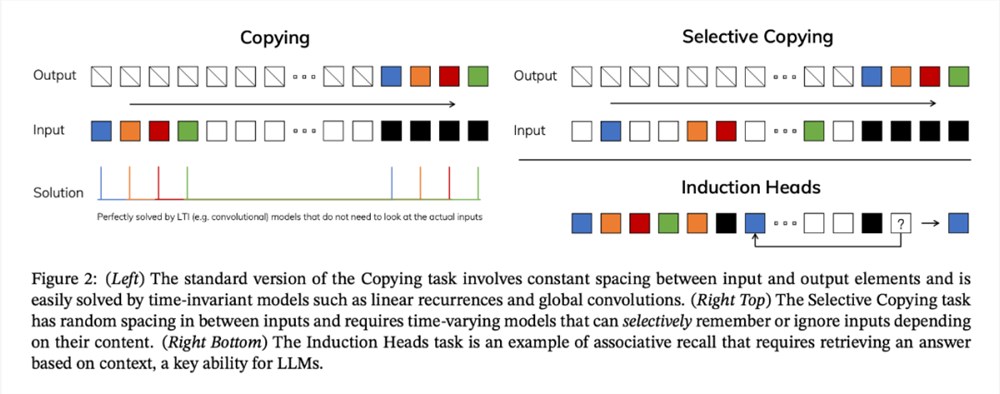
研究者设计了一种简单的选择机制,根据输入对 SSM 参数进行参数化。这样,模型就能过滤掉无关信息,并无限期地记住相关信息。
将选择机制纳入模型的一种方法是让影响序列交互的参数(如 RNN 的递归动力学或 CNN 的卷积核)与输入相关。算法1和2展示了本文使用的主要选择机制。其主要区别在于,该方法只需将几个参数 ∆,B,C 设置为输入函数,并在整个过程中改变张量形状。这些参数现在都有一个长度维度 L ,意味着模型已经从时间不变变为时间可变。

硬件感知算法
上述变化对模型的计算提出了技术挑战。所有先前的 SSM 模型都必须是时间和输入不变的,这样才能提高计算效率。为此,研究者采用了一种硬件感知算法,通过扫描而不是卷积来计算模型,但不会将扩展状态具体化,以避免在 GPU 存储器层次结构的不同级别之间进行 IO 访问。由此产生的实现方法在理论上(与所有基于卷积的 SSM 的伪线性相比,在序列长度上呈线性缩放)和现有硬件上都比以前的方法更快(在 A100GPU 上可快达3倍)。
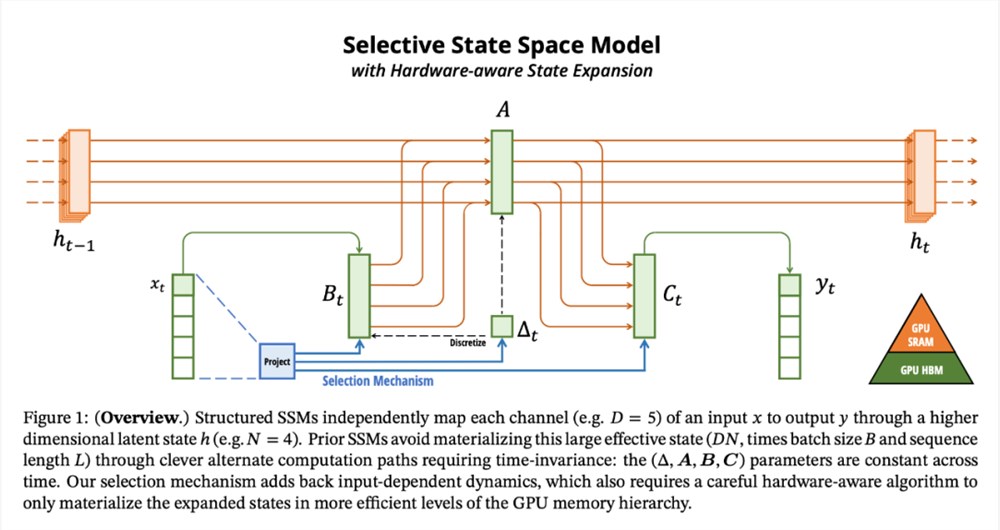
架构
研究者将先前的 SSM 架构设计与 Transformer 的 MLP 块合并为一个块,从而简化了深度序列模型架构,形成了一种包含选择性状态空间的简单、同质的架构设计(Mamba)。
与结构化 SSM 一样,选择性 SSM 也是一种独立的序列变换,可以灵活地融入神经网络。H3架构是著名的同质化架构设计的基础,通常由线性注意力启发的块和 MLP(多层感知器)块交错组成。
研究者简化了这一架构,将这两个部分合二为一,均匀堆叠,如图3。他们受到门控注意力单元(GAU)的启发,该单元也对注意力做了类似的处理。
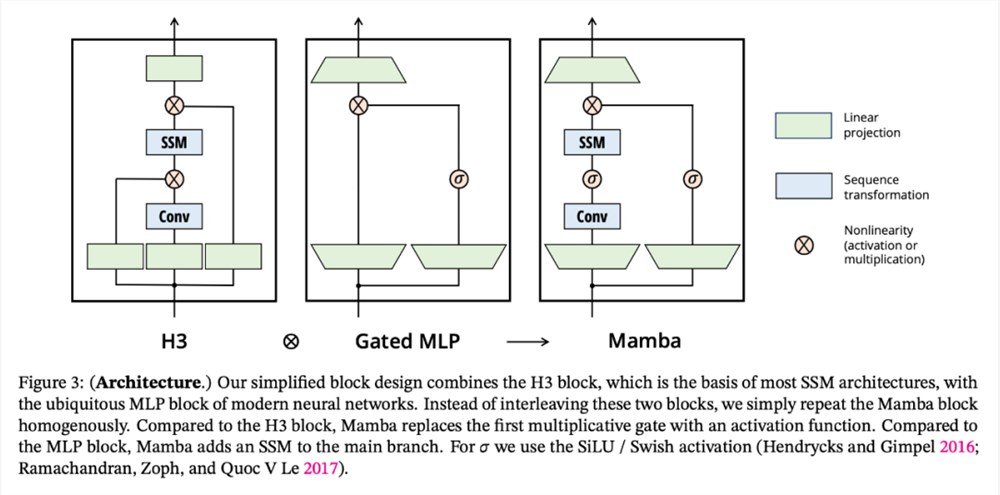
选择性 SSM 以及 Mamba 架构的扩展是完全递归模型,几个关键特性使其适合作为在序列上运行的通用基础模型的骨干:
高质量:选择性为语言和基因组学等密集模型带来了强大的性能。
快速训练和推理:在训练过程中,计算量和内存与序列长度成线性关系,而在推理过程中,由于不需要缓存以前的元素,自回归展开模型每一步只需要恒定的时间。
长上下文:质量和效率共同提高了实际数据的性能,序列长度可达100万。
实验评估
实证验证了 Mamba 作为通用序列基础模型骨干的潜力,无论是在预训练质量还是特定领域的任务性能方面,Mamba 都能在多种类型的模态和环境中发挥作用:
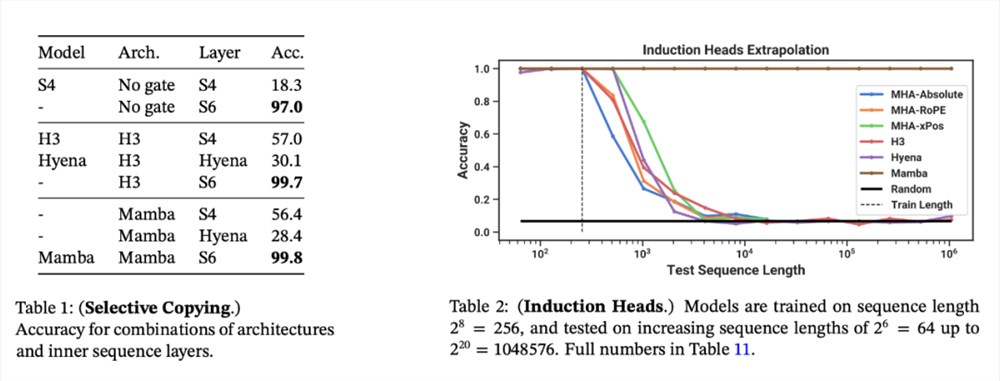
合成任务。在复制和感应头等重要的语言模型合成任务上,Mamba 不仅能轻松解决,而且能推断出无限长的解决方案(>100万 token)。
音频和基因组学。在音频波形和 DNA 序列建模方面,Mamba 在预训练质量和下游指标方面都优于 SaShiMi、Hyena、Transformer 等先前的 SOTA 模型(例如,在具有挑战性的语音生成数据集上将 FID 降低了一半以上)。在这两种情况下,它的性能随着上下文长度的增加而提高,最高可达百万长度的序列。
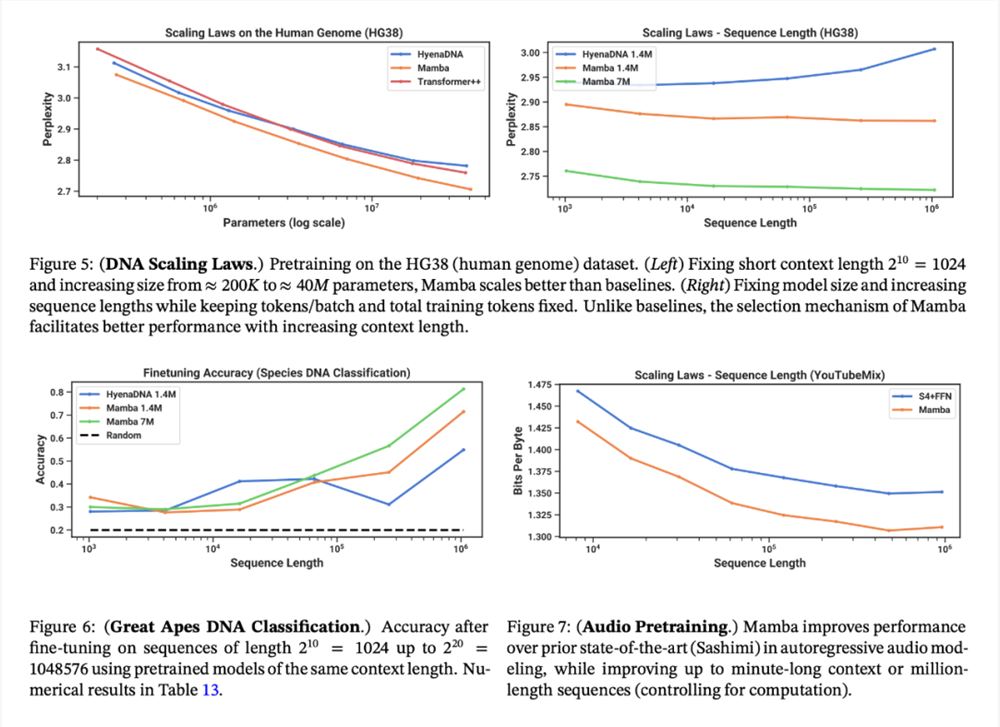
语言建模。Mamba 是首个线性时间序列模型,在预训练复杂度和下游评估方面都真正达到了 Transformer 质量的性能。通过多达1B 参数的缩放规律,研究者发现 Mamba 的性能超过了大量基线模型,包括 LLaMa 这种非常强大的现代 Transformer 训练配方。
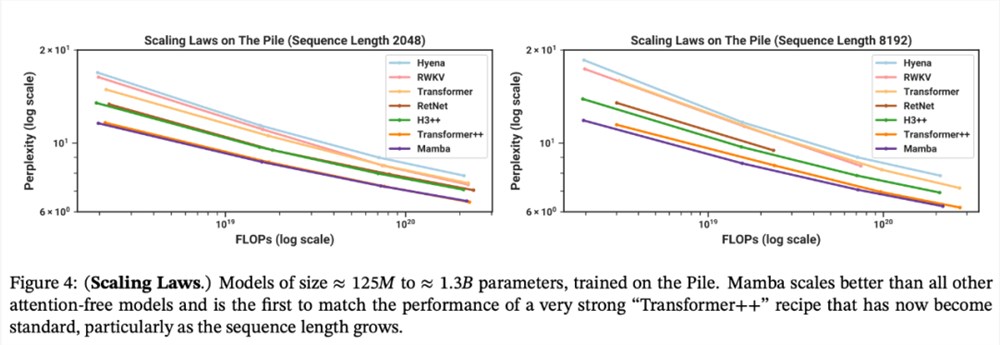
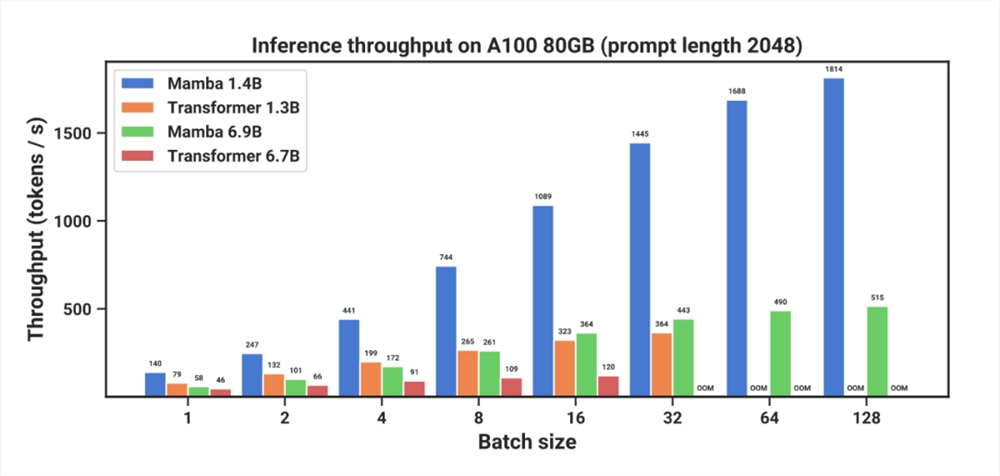
与类似规模的 Transformer 相比,Mamba 具有5倍的生成吞吐量,而且 Mamba-3B 的质量与两倍于其规模的 Transformer 相当(例如,与 Pythia-3B 相比,常识推理的平均值高出4分,甚至超过 Pythia-7B)。
推荐站点
 88分类目录
88分类目录88分类目录专业提供网站网址免费提交收录,88分类目录是采用开放导航式的网站大全,收录国内外各行业优秀的网站网址,让网站在各大搜索引擎收录快排名靠前。
www.88dir.com 66网站目录
66网站目录66网站目录是免费收录各行业优秀网站,提供网站分类目录检索,关键字搜索,提交网站即可免费推广,增加外链,提升网站流量。
www.66dir.com 265分类目录
265分类目录网址目录网站网址大全,收集正规的中文官方网站,用户自主提交网站,265分类目录努力打造互动新颖的网站分类目录导航收录平台
www.265dir.com YY分类目录
YY分类目录YY分类目录全人工编辑的开放式网站分类目录,收录国内外、各行业优秀网站,旨在为用户提供网站分类目录检索、优秀网站参考、网站推广服务。
www.yydir.com 名人百科网
名人百科网名人百科网(mrenbaike.net)--为大家提供各行各业的名人资料、资讯、图片等,致力于打造国内专业的名人百科平台!
www.mrenbaike.net 菜鸟教程
菜鸟教程菜鸟教程提供了基础编程技术教程。 菜鸟教程的 Slogan 为:学的不仅是技术,更是梦想! 记住:再牛逼的梦想也抵不住傻逼似的坚持! 本站域名为 runoob.com, runoob 为 Running Noob 的缩写,意为:奔跑吧!菜鸟。 本站包括了HTML、CSS、Javascript、PHP、C、Python等各种基础编程教程。 同时本站中也提供了大量的在线实例,通过实例,您可以更好地学习如何建站。 本站致力于推广各种编程语言技.
www.runoob.com 中国社会公益网
中国社会公益网陕西省社会公益基金会是经陕西省民政厅批准的公募基金会,下设秘书处、公益项目部、筹款募捐部、宣传策划部、社会活动部、专项基金部、资金管理部、公关联络部、青年志愿者工作委员会、青年志愿者爱心乐团等部门机构
www.cpf.net.cn CNMO科技新媒体
CNMO科技新媒体CNMO=Connect More,致力于通过内容成为人与科技、人与产品、人与品牌、人与服务对接的桥梁,让产业、产品的价值与服务得到专业且有趣的解读和适配,引领用户畅享科技带来的美好生活!
www.cnmo.com 国外主机测评
国外主机测评国外主机测评,国外VPS、云服务器,国外服务器,国外主机的相关优惠信息、商家背景、网络带宽、线路走法、售前和售后技术支持等,是目前最好的一家国外主机评测平台。
www.zhujiceping.com